
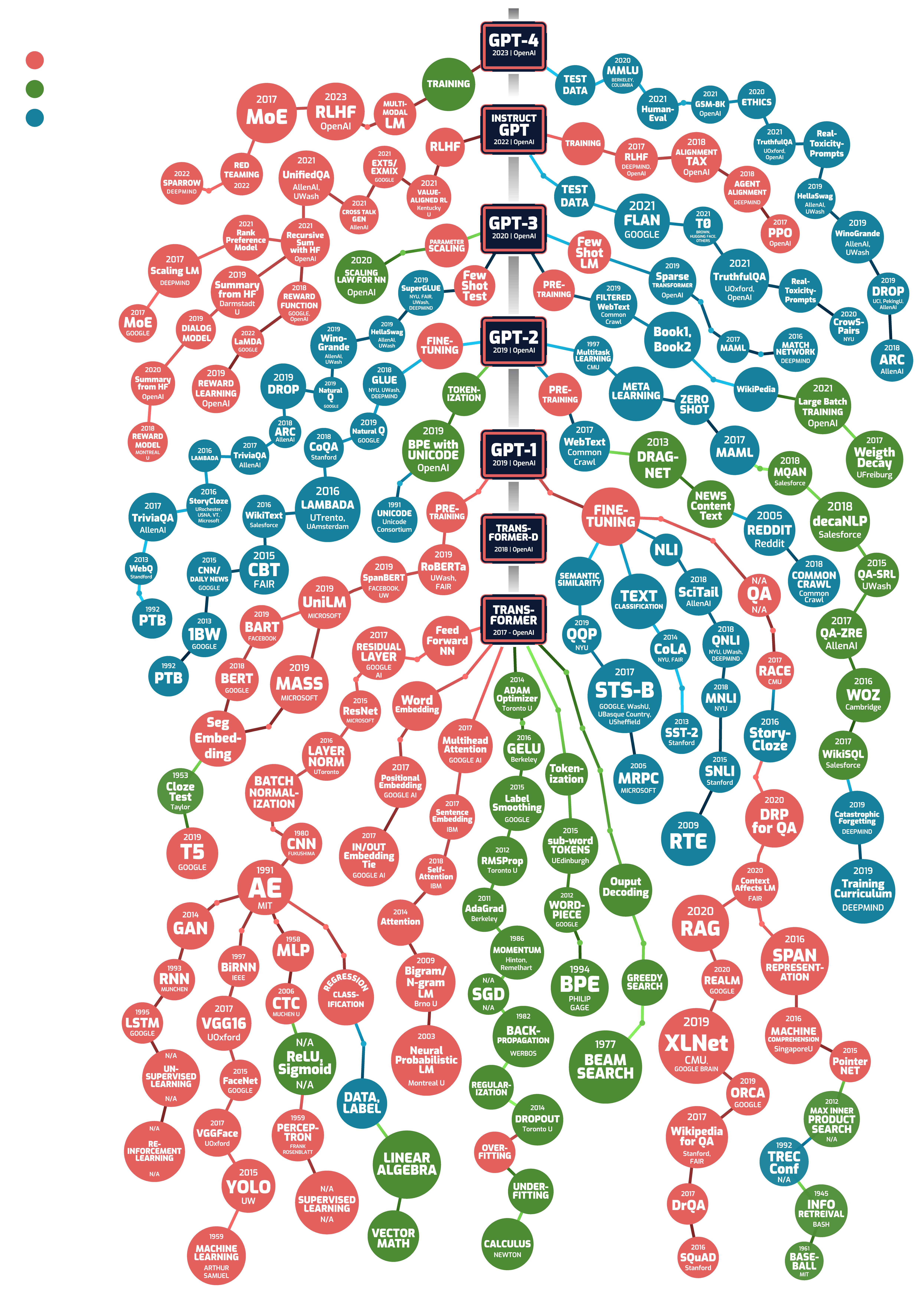
Name: GPT-1
Date: 2018
Source: OpenAI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Pioneered the Generative Pretraining (GPT) approach for text generation. Trained on a large text corpus, it can predict the next word, demonstrating text generation capabilities. This approach paved the way for further development in large language models.
Name: Pre-training
Date: 0
Source: nan
Talent Level: L2
Tech Type: AI/ML
Tech Source: Academic
Summary: Pre-training is a foundational technique in machine learning, particularly in the development of language models. It involves training a model on a large dataset before fine-tuning it on a specific task. During pre-training, a model learns general patterns, structures, and features from the data, which can include text, images, or other types of information. This process enables the model to acquire a broad understanding of the domain, making it more effective and efficient when subsequently trained on smaller, task-specific datasets. Pre-training is crucial for achieving state-of-the-art performance in various applications, such as natural language processing, computer vision, and speech recognition, by leveraging the knowledge gained from vast amounts of data.
Name: RoBERTa
Date: 2019
Source: UWash, FAIR
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: RoBERTa (Robustly optimized BERT approach) is a transformer-based model for natural language understanding, introduced by Facebook AI in 2019. It builds on BERT (Bidirectional Encoder Representations from Transformers) by training on more data and for longer periods with larger mini-batches. RoBERTa removes the Next Sentence Prediction (NSP) task from BERT's pretraining and uses dynamic masking rather than static masking. It achieves state-of-the-art performance on a range of NLP tasks, demonstrating the importance of extensive pretraining and fine-tuning for improving model robustness and accuracy.
Name: SpanBERT
Date: 2019
Source: Facebook, UW
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: SpanBERT is a variant of the BERT model specifically designed for improving span-based tasks in natural language processing (NLP). Introduced by researchers from Facebook AI in 2019, SpanBERT enhances BERT's capabilities by modifying the pretraining objectives to better capture and predict contiguous spans of text. It replaces BERT's Next Sentence Prediction (NSP) task with span boundary objectives, which involve predicting the entire span from its boundaries and reconstructing masked spans. SpanBERT achieves state-of-the-art performance on tasks like question answering and coreference resolution, highlighting its effectiveness in understanding and predicting text spans.
Name: UniLM
Date: 2019
Source: Microsoft
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: UniLM (Unified Language Model) is a versatile transformer-based model developed by Microsoft Research. It is designed to handle various natural language processing (NLP) tasks, including natural language understanding, generation, and translation, within a single framework. UniLM achieves this by leveraging a unified pretraining approach that combines the objectives of different tasks, such as sequence-to-sequence and masked language modeling. This allows the model to generate coherent text sequences and understand context effectively. UniLM has demonstrated state-of-the-art performance on a wide range of NLP benchmarks, showcasing its flexibility and effectiveness in handling diverse language tasks.
Name: MASS
Date: 2019
Source: Microsoft
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: MASS (Masked Sequence to Sequence Pre-training for Language Generation) is a language model developed by Microsoft Research. It introduces a novel pretraining method specifically designed for sequence-to-sequence language generation tasks. In MASS, a portion of the input sequence is masked, and the model is trained to predict the missing part, effectively learning to generate coherent sequences. This approach enhances the model's ability to handle various generation tasks, such as machine translation, text summarization, and text generation. MASS has shown significant improvements in performance over existing methods, demonstrating the effectiveness of masked sequence-to-sequence pretraining for language generation.
Name: BART
Date: 2019
Source: Facebook
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: BART (Bidirectional and Auto-Regressive Transformers) is a language model developed by Facebook AI, designed for natural language understanding and generation. It utilizes a denoising sequence-to-sequence pre-training approach where the model is trained to reconstruct the original text from a corrupted input. This method involves various types of noise, such as token masking, deletion, and shuffling. BART combines the strengths of bidirectional (BERT-like) and autoregressive (GPT-like) models, making it highly effective for tasks like text generation, translation, and summarization. BART achieves state-of-the-art performance on multiple NLP benchmarks, showcasing its robustness and versatility in handling complex language tasks.
Name: BERT
Date: 2018
Source: Google
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: BERT (Bidirectional Encoder Representations from Transformers) is a groundbreaking language model introduced by Google AI. It employs a deep bidirectional transformer architecture, allowing it to capture context from both directions in a text sequence. BERT is pretrained using two main objectives: Masked Language Modeling (MLM), where random words in a sentence are masked and predicted, and Next Sentence Prediction (NSP), where the model learns to understand the relationship between paired sentences. This pretraining approach enables BERT to excel in various natural language understanding tasks, including question answering, sentiment analysis, and named entity recognition, setting new benchmarks across multiple NLP tasks.
Name: Seg Embedding
Date: 2018
Source: Google
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Segment Embedding (Seg Embedding) is a component used in the BERT (Bidirectional Encoder Representations from Transformers) model to differentiate between different segments (or sentences) within a single input sequence. In BERT's pretraining, each input consists of pairs of sentences, which are combined into a single sequence. Segment embeddings are used to indicate whether each token belongs to the first sentence (segment A) or the second sentence (segment B). This distinction is crucial for tasks like Next Sentence Prediction (NSP), where understanding the relationship between two sentences is essential. Segment embeddings, along with token and positional embeddings, enable BERT to effectively learn contextual representations and relationships between sentences during pretraining.
Name: Cloze Test
Date: 1953
Source: Taylor
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: The Cloze Test is a linguistic assessment method used to evaluate language comprehension and proficiency. In this test, participants are presented with a passage of text in which certain words are removed and replaced with blanks. The participants must then fill in the blanks with the appropriate words based on the context of the remaining text. The Cloze Test is commonly used in language education and psycholinguistics to measure reading ability, vocabulary knowledge, and overall language understanding. It serves as a diagnostic tool to identify areas of strength and weakness in a learner's linguistic abilities.
Name: T5
Date: 2019
Source: Google
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: T5 (Text-To-Text Transfer Transformer) is a transformer-based language model introduced by Google Research, designed to handle various natural language processing tasks using a unified text-to-text framework. Presented in the paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer," T5 converts all tasks, such as translation, summarization, and classification, into a text-to-text format. This approach simplifies the model architecture and leverages transfer learning more effectively. T5 is pretrained on a large, diverse dataset using a denoising objective, where corrupted input sequences are reconstructed. It achieves state-of-the-art performance across multiple benchmarks, demonstrating the effectiveness of the unified text-to-text approach for various NLP tasks.
Name: Tranformer-D
Date: 2018
Source: Google
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Transformer-D is a variation of the transformer architecture introduced in the paper "Generating Wikipedia by Summarizing Long Sequences." It is designed to handle long sequences of text by incorporating specialized mechanisms that improve the model's ability to generate coherent and contextually accurate summaries. Transformer-D addresses the challenge of managing long dependencies and maintaining the flow of information across lengthy inputs, which is critical for tasks like document summarization and long-form text generation. By enhancing the standard transformer model, Transformer-D achieves superior performance in summarizing extensive texts, demonstrating its capability to produce high-quality summaries from long input sequences.
Name: Transformer
Date: 2017
Source: Google AI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: The Transformer architecture, a novel approach using self-attention for dependency modeling in sequence-to-sequence tasks. This revolutionized NLP due to its parallelization capabilities and effectiveness, making it a foundational model for many NLP tasks.
Name: Feed Forward NN
Date: 2017
Source: Google AI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: A feedforward neural network is a basic architecture where information flows in one direction, from input to output, through hidden layers. It's a building block in many models, including transformers. Transformers rely on a specific type of feedforward network called a Multi-Layer Perceptron (MLP) within their encoder and decoder blocks. This MLP helps process the information extracted by the transformer's self-attention mechanism, allowing the model to learn complex relationships within the data.
Name: Residual layer
Date: 2017
Source: Google AI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: In deep learning, a residual layer is a technique used in architectures like convolutional neural networks (CNNs) to address vanishing gradients. It allows the network to learn the identity function (simply outputting the input unchanged) alongside more complex transformations. This helps with training very deep networks by making it easier for them to learn and improve upon the information passed through previous layers.
Name: ResNet
Date: 2015
Source: Microsoft
Talent Level: L1
Tech Type: AI/ML
Tech Source: Industry
Summary: Resnet, short for Residual Neural Network, is a type of Convolutional Neural Network (CNN) architecture specifically designed to overcome challenges in training very deep networks. Traditional CNNs suffer from vanishing gradients, where information gets lost as it passes through many layers. Resnet tackles this by introducing skip connections. These connections bypass some layers and add the original input directly to the output of those layers. This allows the network to learn more complex transformations while also preserving the ability to learn the identity function (simply outputting the input unchanged). This approach enables Resnets to achieve superior performance on various computer vision tasks compared to traditional CNNs, especially when dealing with very deep architectures.
Name: Layer Norm
Date: 2016
Source: UToronto
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Layer normalization is a technique in machine learning that stabilizes the training process of neural networks. It works by normalizing the activations (outputs) of each neuron within a hidden layer, independently across different training examples. This helps address a phenomenon called internal covariate shift, where the distribution of activations can change throughout training, hindering learning. Layer normalization improves gradient flow, allowing for faster training and better generalization performance of the model.
Name: Batch Normalization
Date: 2015
Source: Google
Talent Level: L1
Tech Type: AI/ML
Tech Source: Industry
Summary: Batch normalization is a technique used during training in deep neural networks. It addresses a problem called internal covariate shift, where the distribution of data changes between layers as the network learns. Batch normalization normalizes the activations of each layer, making the training process faster and more stable. This allows the network to learn from a wider range of weight initializations and helps prevent overfitting.
Name: CNN
Date: 1980
Source: Fukushima
Talent Level: L1
Tech Type: AI/ML
Tech Source: Industry
Summary: CNN, or Convolutional Neural Network, is a type of deep learning model excelling at tasks involving grids of data, like images. It extracts features through convolutional layers that slide over the input, identifying patterns and edges. Pooling layers then summarize this information. Fully-connected layers at the end use these features for classification or other tasks. CNNs are particularly effective in computer vision applications like image recognition and object detection.
Name: AE
Date: 1991
Source: MIT
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Autoencoders are unsupervised learners that compress data into a lower-dimensional space and then try to recreate the original data from that compressed version. This process helps them learn efficient representations of the data, useful for dimensionality reduction or anomaly detection.
Name: GAN
Date: 2014
Source: Montreal U
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Generative Adversarial Networks (GANs) are a type of machine learning system that uses two competing neural networks to create new data. One network, the generator, tries to produce realistic data based on a training set, while the other network, the discriminator, tries to identify if the data is real or generated. This competition pushes both networks to improve, resulting in the generator creating increasingly realistic new data, like images, music, or even text.
Name: RNN
Date: 1993
Source: Munchen
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Recurrent Neural Networks (RNNs) are a type of deep learning model that excels at handling sequential data like text or speech. Unlike traditional neural networks, RNNs can remember past inputs thanks to a hidden state. This allows them to analyze sequences and make predictions based on the context, making them ideal for tasks like machine translation, speech recognition, and caption generation.
Name: LSTM
Date: 1995
Source: Google
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: LSTMs, or Long Short-Term Memory networks, are a special kind of Recurrent Neural Network (RNN) designed to overcome a weakness in RNNs. LSTMs have a built-in memory and control mechanisms that allow them to learn from long sequences of data. This makes them particularly good at tasks where understanding long-term context is important, like machine translation, speech recognition, and handwriting analysis.
Name: BiRNN
Date: 1997
Source: IEEE
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: BiRNN, short for Bidirectional Recurrent Neural Network, is a type of RNN that tackles sequences from both directions. Unlike a standard RNN that only looks at the past, a BiRNN considers both past and future elements in a sequence. This extra context allows BiRNNs to better understand the entire sequence, making them useful for tasks like sentiment analysis, speech recognition, and machine translation where surrounding information is crucial.
Name: VGG16
Date: 2014
Source: UOxford
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: VGG16 is a deep learning model, specifically a Convolutional Neural Network (CNN), known for its accuracy in image recognition and classification. It analyzes images through a series of stacked layers, progressively extracting higher-level features. VGG16 is famous for its depth (16 layers) and is often used as a pre-trained model to jumpstart training on new image recognition tasks.
Name: FaceNet
Date: 2015
Source: Google
Talent Level: L1
Tech Type: AI/ML
Tech Source: Industry
Summary: Facenet is a deep learning system for face recognition. It takes a person's face image and creates a unique 128-dimensional code, like a fingerprint for their face. This code captures key facial features and distances between them. Faces from the same person will have similar codes, even under variations like lighting or pose. Facenet is a powerful tool for building face recognition applications.
Name: VGGFace
Date: 2017
Source: UOxford
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: VGGFace refers to a family of pre-trained models specifically designed for face recognition tasks in machine learning. Based on the VGG16 architecture, these models are trained on massive datasets of labeled faces. VGGFace excels at extracting facial features and can be used for various tasks like face detection, recognition, and verification. It's often used as a starting point for fine-tuning on specific face recognition problems.
Name: YOLO
Date: 2015
Source: UW
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: YOLO, standing for "You Only Look Once," is a machine learning algorithm for real-time object detection. Unlike some methods, YOLO uses a single neural network to efficiently analyze the entire image at once. It divides the image into a grid and predicts bounding boxes and class probabilities for objects within each grid cell. This makes YOLO super fast for applications like self-driving cars or video surveillance where real-time processing is crucial. However, it can be less accurate than some other object detectors.
Name: CTC
Date: 2006
Source: Muchen U
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: CTC, or Connectionist Temporal Classification, is a technique used in machine learning specifically for sequence recognition tasks, often involving audio or text data. Unlike other methods, CTC doesn't require perfect alignment between the input sequence (like speech) and the output (like text). It considers all possible alignments and picks the most likely one, making it robust for dealing with variations in speech speed or pronunciation. CTC is commonly used in speech recognition systems.
Name: ReLU, Sigmoid
Date: 0
Source: nan
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: ReLU (Rectified Linear Unit) and sigmoid are activation functions used in machine learning's artificial neurons. They determine how the neuron processes information. ReLU acts like a switch, only firing if the input is positive. This makes it faster to compute and avoids vanishing gradients in deep networks. Sigmoid squishes values between 0 and 1, but can suffer from vanishing gradients and may not be ideal for all tasks.
Name: MLP
Date: 1958
Source: Frank Rosenblatt
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: In machine learning, an MLP, or Multilayer Perceptron, is a fundamental type of artificial neural network. It consists of layers of interconnected nodes, inspired by the human brain. Unlike simpler models, MLPs have multiple "hidden layers" between the input and output layers. These layers allow MLPs to learn complex patterns in data that aren't easily separated with straight lines. This makes them useful for tasks like image recognition, spam filtering, and even playing games.
Name: Perceptron
Date: 1959
Source: Frank Rosenblatt
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: A perceptron is the building block of neural networks in machine learning. It's a simple algorithm for binary classification tasks. Imagine a single neuron receiving inputs, like features of an image. The perceptron assigns weights to these inputs and sums them. If the sum is above a certain threshold, it outputs a 1, otherwise a 0. Perceptrons learn by adjusting weights to improve their classification accuracy. While limited to binary problems, they are a foundational concept for understanding more complex neural networks.
Name: Supervised learning
Date: 0
Source: nan
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Supervised learning is a machine learning technique where algorithms learn from labeled data. This data acts like a training manual, with clear examples of inputs and their corresponding desired outputs. By analyzing these pairs, the algorithm learns the relationship between them and can then predict outputs for new, unseen data. Imagine a student learning shapes from a teacher. Supervised learning works similarly, allowing machines to learn and make predictions based on labeled examples.
Name: Unsupervised learning
Date: 0
Source: nan
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: In unsupervised machine learning, algorithms work with data that lacks predefined labels or categories. Unlike supervised learning where the data comes with clear instructions, unsupervised learning algorithms are tasked with finding hidden patterns and structures within the data itself. They achieve this by analyzing the data to group similar elements together, identify hidden categories, or find anomalies. This allows them to uncover interesting insights and prepare the data for further analysis or even generate entirely new data.
Name: Reinforcement learning
Date: 0
Source: nan
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: In reinforcement learning, an agent interacts with an environment by taking actions and receiving rewards. Through trial and error, the agent learns which actions lead to the most reward, constantly refining its strategy. This method mimics how humans learn by experimentation and is useful for tasks where the best course of action isn't explicitly defined.
Name: Regression, classification
Date: 0
Source: nan
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Regression and classification are two fundamental tasks in machine learning. Regression algorithms predict continuous values, like housing prices or weather forecasts. Classification algorithms, on the other hand, predict discrete categories, such as whether an email is spam or an image contains a cat. Essentially, regression predicts "what" while classification predicts "which".
Name: Machine learning
Date: 1959
Source: Arthur Samuel
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Machine learning is a type of artificial intelligence where computers learn from data without being explicitly programmed. By analyzing data, they can identify patterns and make predictions on new data, becoming increasingly accurate over time.
Name: Linear Algebra
Date: 0
Source: nan
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Linear algebra is the branch of mathematics focused on vectors, matrices, and linear equations. It provides the foundation for many machine learning algorithms, allowing us to represent data, perform transformations, and solve complex problems efficiently.
Name: Data, Label
Date: 0
Source: nan
Talent Level: L1
Tech Type: Data
Tech Source: Academic
Summary: In machine learning, data is the raw material, like images, text, or numbers. It holds the information the model needs to learn from. Labels are added information that tells the model what the data represents. Think of data as ingredients and labels as instructions in a recipe � both are crucial for the model to learn and make predictions.
Name: Vector math
Date: 0
Source: nan
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Vector math extends regular arithmetic to objects with both magnitude (size) and direction. Imagine arrows representing forces or velocities. Vector addition considers both the length and direction of the arrows to find a resultant arrow. This allows us to analyze and manipulate quantities with direction, crucial in physics, engineering, and many machine learning applications.
Name: Word Embedding
Date: 2013
Source: Google
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Word Embedding is a machine learning technique that maps words or phrases from a vocabulary into vectors of real numbers, allowing similar words to have similar numerical representations. This is crucial in natural language processing tasks, as it helps algorithms understand semantic and syntactic similarities between words.
Name: Positional Embedding
Date: 2017
Source: Google AI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Positional Embedding is a technique used in Natural Language Processing that assigns each word or token in a sequence a vector representation based on its position, enabling the model to understand the order of words in a sequence. This is crucial for tasks such as translation or sentence completio where the positioning of words impacts the meaning.
Name: In/out Embedding Tie
Date: 2017
Source: Google AI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: In/out Embedding Tie refers to a method in machine learning where the same weights are shared between the input-to-hidden and hidden-to-output layers of a model, essentially "tying" these two layers together. This technique can reduce the number of parameters in the model, potentially improving the efficiency and performance of the model.
Name: Multihead attention
Date: 2017
Source: Google AI
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Multihead attention is a mechanism in transformer models that allows the model to focus on different positions of the input sequence simultaneously, thereby capturing various aspects of the information. It does so by splitting the input data into multiple 'heads', each of which independently learns different types of attention, before being recombined to produce the final output.
Name: Sentence embedding
Date: 2017
Source: IBM
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Sentence embedding is a technique in natural language processing where sentences are mapped into vectors of real numbers, essentially creating a mathematical representation of the sentence. This facilitates tasks such as semantic similarity measurement, text classification, and other language-related machine learning applications.
Name: Self-Attention
Date: 2018
Source: IBM
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Self-Attention is a mechanism in machine learning models that allows them to focus on relevant parts of the input for making predictions. It assigns different importance (attention) to different parts of the input, enabling the model to make better context-aware decisions.
Name: Attention
Date: 2014
Source: JacobsU, UMontreal
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Attention is a mechanism in machine learning models that allows them to focus on specific aspects of complex inputs, improving the accuracy of results. It's often used in natural language processing to help models understand context, remember previous information, and produce more accurate translations or responses.
Name: Bigram/N-gram LM
Date: 2009
Source: Brno U
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: A Bigram/N-gram Language Model (LM) is a type of statistical language model used in natural language processing that predicts the probability of a word given the previous 'N-1' words in a sentence. It's called a 'bigram' when N=2, and 'N-gram' for N>2, representing sequences of words or letters to anticipate and better understand context.
Name: Neural Probabilistic LM
Date: 2003
Source: Montreal U
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Neural Probabilistic Language Model (NPLM) is a type of language model that leverages neural networks to predict the next word in a sequence based on the words that precede it. It uses the context of the sentence (previous words) to form a high-dimensional representation, which it then uses to compute the probability distribution of the next word.
Name: ADAM Optimizer
Date: 2014
Source: Toronto U
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: The ADAM (Adaptive Moment Estimation) Optimizer is a machine learning algorithm that calculates individual adaptive learning rates for different parameters, combining the advantages of two other extensions of stochastic gradient descent: AdaGrad and RMSProp. It's particularly effective in settings where data and/or resources are sparse and computation is expensive.
Name: GELU
Date: 2016
Source: Berkeley
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: GELU, or Gaussian Error Linear Unit, is a type of activation function used in artificial neural networks that helps decide whether and how much a neuron should be activated. It is known for its efficiency, as it allows for fast and accurate training, and its ability to mitigate the vanishing gradient problem, which can slow down or prevent learning.
Name: Label Smoothing
Date: 2015
Source: Google
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: Label Smoothing is a regularization technique in machine learning that prevents the model from becoming too confident about the class labels by assigning a small amount of the total probability to all other labels. This technique helps to mitigate overfitting and improves generalization of the model by making the training process less sensitive to the exact values of the labels.
Name: RMSProp
Date: 2012
Source: Toronto U
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: RMSProp (Root Mean Square Propagation) is an adaptive learning rate optimization algorithm for neural networks, designed to attenuate the aggressively decreasing learning rate in conventional gradient descent methods. It adjusts the learning rate by dividing it by an exponentially decaying average of squared gradients, providing an individual learning rate for each parameter, effectively resolving the issue of diminishing learning rates in deep learning.
Name: AdaGrad
Date: 2011
Source: Berkeley
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: AdaGrad (Adaptive Gradient Algorithm) is an optimization algorithm in machine learning that adapts the learning rate to the parameters, performing smaller updates for parameters associated with frequently occurring features and larger updates for parameters associated with infrequently occurring features. It is particularly useful in scenarios where data is sparse and the learning rate needs to be adaptive.
Name: Momentum
Date: 1986
Source: Hinton, Remelhart
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Momentum is a technique used in optimization algorithms, such as Gradient Descent, to speed up learning and avoid local minima by adding a fraction of the direction of the previous step to a current step. This way, the algorithm accumulates the gradient of the past steps to determine the direction to go, somewhat similar to a ball rolling downhill.
Name: SGD
Date: 0
Source: nan
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Stochastic Gradient Descent (SGD) is an iterative algorithm used in machine learning and deep learning to find the optimal parameters that minimize a function, often a loss function. Unlike the standard Gradient Descent that uses all data points to compute the gradient, SGD randomly selects a batch of data points per iteration, significantly speeding up the process and reducing computational load.
Name: Backpropagation
Date: 1982
Source: Werbos
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Backpropagation is a machine learning algorithm used in neural networks to adjust the weights and biases in response to errors, effectively "learning" from the mistakes. It does so by propagating the error backwards through the network, hence the name, and then using gradient descent to iteratively fine-tune the network parameters until the model's predictions are as accurate as possible.
Name: Regularization
Date: 0
Source: nan
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Regularization is a technique used in machine learning models to prevent overfitting by adding a penalty term to the loss function, which in turn reduces the complexity of the model. It helps to maintain a balance between bias and variance, ensuring that the model generalizes well on unseen data.
Name: Dropout
Date: 2014
Source: Toronto U
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Dropout is a regularization technique used in neural networks to prevent overfitting by randomly dropping out, or deactivating, a proportion of neurons during training. This forces the network to learn more robust features that are useful in conjunction with many different random subsets of the other neurons.
Name: Overfitting
Date: 0
Source: nan
Talent Level: L1
Tech Type: AI/ML
Tech Source: Academic
Summary: Overfitting is a modeling error in machine learning when a model is excessively complex and performs well on training data but poorly on new, unseen data. It happens when the model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data.
Name: Underfitting
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Underfitting is a concept in machine learning where a model fails to capture the underlying pattern of the data, usually due to its oversimplicity or lack of sufficient training data. This leads to poor performance on both training and test data, as the model lacks the complexity necessary to understand and predict accurate outcomes.
Name: Calculus
Date: 0
Source: Newton
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Calculus is a branch of mathematics that studies continuous change, primarily through the concepts of differentiation and integration. Differentiation measures the rate of change in a function, while integration accumulates the quantities produced by a function.
Name: Tokenization
Date: 0
Source: nan
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: Tokenization is a process in natural language processing (NLP) that splits a large amount of text into smaller parts called tokens. These tokens help in understanding the context or developing a model to analyze the text.
Name: sub-word tokens
Date: 2015
Source: UEdinburgh
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: Sub-word tokens are smaller units derived from whole words, often used in natural language processing to handle unknown or rare words and improve model performance. They can range from single characters to common word stems or suffixes, allowing a model to generalize from known tokens to unseen ones.
Name: WordPiece
Date: 2012
Source: Google
Talent Level: L2
Tech Type: Others
Tech Source: Industry
Summary: WordPiece is a subword tokenization algorithm used in natural language processing, which breaks words into smaller units, allowing the model to handle rare or unseen words more effectively by understanding their components. It helps in reducing the size of the vocabulary and improving the computational efficiency of language models.
Name: BPE
Date: 1994
Source: Philip Gage
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Byte Pair Encoding (BPE) is a data compression technique that replaces the most common pair of bytes in a dataset with a single byte not previously used. In natural language processing, BPE is used to split words into subwords to allow the model to handle rare and unseen words better.
Name: Ouput Decoding
Date: 0
Source: nan
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: Output decoding is the process of interpreting the output received from a system, often translating it from machine code into a human-readable format. It's a crucial step in digital communication and data processing, where the decoded information is used for further analysis or decision making.
Name: Greedy Search
Date: 0
Source: nan
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: Greedy Search is an algorithmic paradigm that follows the problem-solving heuristic of making the locally optimal choice at each stage with the hope of finding a global optimum. It is used in optimization problems where the goal is to make the most optimal decision at each step, reducing the problem's complexity.
Name: Beam Search
Date: 1977
Source: nan
Talent Level: L2
Tech Type: Others
Tech Source: Academic
Summary: Beam Search is an algorithm used in many natural language processing tasks that reduces the complexity of searching through all possible sequences by only keeping track of the most promising sequences, referred to as "beams". This approach helps to optimize computational efficiency without significantly sacrificing the quality of results.
Name: Fine-tuning
Date: 0
Source: nan
Talent Level: L2
Tech Type: AI/ML
Tech Source: Academic
Summary: Fine-tuning is a transfer learning technique where a pre-trained model is further trained on a specific task or domain with task-specific data. It involves updating the parameters of the pre-trained model using a smaller dataset, allowing the model to adapt to the nuances of the target task while leveraging the knowledge learned from the pre-training phase.
Name: QA
Date: 0
Source: nan
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Question answering (QA) is a natural language processing task where a model is tasked with providing relevant answers to questions posed in natural language. It involves understanding the question, retrieving relevant information from a given context or knowledge base, and generating an accurate response.
Name: RACE
Date: 2017
Source: CMU
Talent Level: L2
Tech Type: AI/ML
Tech Source: Academic
Summary: The RACE dataset is a large-scale English language reading comprehension dataset, designed for evaluating machine reading comprehension models. It contains diverse texts and questions from various sources, including fictional and non-fictional texts, along with multiple-choice answers.
Name: StoryCloze
Date: 2016
Source: URochester, USNA, VT, Microsoft
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: The StoryCloze Test is a dataset for evaluating story understanding and script learning, where models are given the beginning of a story and must choose the correct ending from two options. It assesses the ability of models to generate coherent and contextually appropriate narrative continuations.
Name: DRP for QA
Date: 2020
Source: FAIR, UWash, PrincetonU
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: Dense Passage Retrieval (DPR) is a technique used in open-domain question answering systems to efficiently retrieve relevant passages from a large corpus of documents. It involves encoding passages and questions into dense representations and using similarity search methods to identify relevant passages.
Name: Context affects LM
Date: 2020
Source: FAIR
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: The study delves into the nuanced relationship between contextual cues and the accuracy of language models in making factual predictions. It scrutinizes how variations in surrounding text can profoundly shape the models' interpretations, shedding light on the pivotal role of context in refining the reliability of language model outputs.
Name: RAG
Date: 2020
Source: FAIR, UWash, PrincetonU
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: Retrieval-Augmented Generation (RAG) is a framework developed by Facebook for question answering tasks, which combines retrieval-based and generation-based approaches. It retrieves relevant passages from a large corpus and generates answers conditioned on both the input question and retrieved passages.
Name: REALM
Date: 2020
Source: Google
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: REALM (Retrieval-Augmented Language Model) is a language model developed by Google that integrates a dense retrieval mechanism to enhance its understanding of natural language. It leverages retrievers to retrieve relevant information from a large-scale knowledge base during inference, improving its performance on various NLP tasks.
Name: XLNet
Date: 2019
Source: CMU, Google Brain
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: XLNet is a pre-trained language model developed by Google, based on the Transformer architecture, that achieves state-of-the-art results on various natural language processing tasks. It employs permutation-based training to capture bidirectional context and overcome limitations of traditional pre-training techniques like BERT.
Name: ORCA
Date: 2019
Source: Google
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: ORCA (Open Retrieval Chatbot) is a chatbot framework developed by Google that integrates retrieval-based methods for generating responses in conversation. It utilizes passage retrieval techniques to find relevant information from a large knowledge base and generate contextually appropriate responses.
Name: Wikipedia for QA
Date: 2017
Source: Stanford, FAIR
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: Wikipedia for Question Answering is a dataset developed by Stanford University for training and evaluating question answering models. It consists of questions paired with relevant passages from Wikipedia, allowing models to learn to extract answers from structured text.
Name: DrQA
Date: 2017
Source: Stanford, FAIR
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: DrQA (Document Reader Question Answering) is a question answering system developed by Stanford University. It uses a combination of information retrieval and machine reading techniques to find relevant documents from a large corpus and extract answers to questions from them.
Name: SQuAD
Date: 2016
Source: Stanford
Talent Level: L2
Tech Type: AI/ML
Tech Source: Academic
Summary: The Stanford Question Answering Dataset (SQuAD) is a benchmark dataset for question answering tasks, consisting of questions posed on Wikipedia articles where the answer is a segment of text from the corresponding passage. It is widely used for training and evaluating question answering models.
Name: Span representation
Date: 2016
Source: UWash, Tel-AvivU, Google
Talent Level: L2
Tech Type: AI/ML
Tech Source: Industry
Summary: Span representation refers to the way a portion of text is encoded or represented in a machine learning model, often used in tasks like question answering where the model needs to identify spans of text that answer a given question.
Name: Machine comprehension
Date: 2016
Source: SingaporeU
Talent Level: L2
Tech Type: AI/ML
Tech Source: Academic
Summary: Machine comprehension involves training models to understand and answer questions about a passage of text. It's a subfield of natural language processing focused on teaching machines to extract information from written sources.
Name: Pointer Net
Date: 2015
Source: Google Brain, Berkeley
Talent Level: L2
Tech Type: AI/ML
Tech Source: Collaborative
Summary: Pointer Networks are a type of neural network architecture designed to handle variable-sized inputs and outputs by learning to point to specific elements in a sequence. They are commonly used in tasks like sequence-to-sequence learning and combinatorial optimization.
Name: Max Inner Product Search
Date: 2012
Source: nan
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Maximum Inner Product Search (MIPS) is a search algorithm used to find the vectors in a database that have the highest inner product with a query vector. It's often employed in applications like recommendation systems and information retrieval.
Name: TREC Conf
Date: 1992
Source: nan
Talent Level: L1
Tech Type: Data
Tech Source: Industry
Summary: The TREC Conference (Text REtrieval Conference) is an annual event organized by the National Institute of Standards and Technology (NIST) and the U.S. Department of Defense. It aims to support research within the information retrieval community by providing the infrastructure necessary for large-scale evaluation of text retrieval methodologies. Since its inception in 1992, TREC has facilitated advancements in search technologies through standardized benchmarking and shared tasks. Participants are given datasets and tasked with developing and evaluating systems to retrieve relevant information. The conference covers various tracks, including web search, question answering, and more specialized areas like legal and biomedical text retrieval. TREC's collaborative environment has been instrumental in driving progress and innovation in the field of information retrieval.
Name: Info Retreival
Date: 1945
Source: Bash
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: Information Retrieval (IR) is the process of obtaining relevant information from large repositories, such as databases or the internet, based on user queries. It encompasses a wide range of tasks including search engine development, document retrieval, and data mining. IR systems use algorithms to match user queries with indexed documents, ranking them by relevance using techniques like keyword matching, semantic analysis, and machine learning. Applications of IR extend to various domains, including web search engines, digital libraries, and enterprise search solutions. The field continually evolves, integrating advancements in natural language processing and artificial intelligence to improve the accuracy and efficiency of information retrieval processes.
Name: Baseball
Date: 1961
Source: MIT
Talent Level: L1
Tech Type: Others
Tech Source: Academic
Summary: BASEBALL is an early automatic question-answering system developed to respond to queries about baseball games. Described in the paper "BASEBALL: An Automatic Question-Answerer," this system was one of the pioneering efforts in natural language processing. It used a database of facts about baseball games and employed syntactic parsing to understand and answer user questions. BASEBALL demonstrated the feasibility of automated question answering by accurately retrieving information based on natural language queries, setting the groundwork for future advancements in AI-driven information retrieval and natural language understanding systems.
Name: NLI
Date: 0
Source: nan
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: Natural Language Inference (NLI) is the task of determining the logical relationship between two pieces of text, typically referred to as the premise and the hypothesis. It involves classifying whether the hypothesis can be inferred from the premise, often categorized into entailment, contradiction, or neutral.
Name: SciTail
Date: 2018
Source: AllenAI
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The SciTail dataset is a textual entailment dataset created from multiple-choice science exams and web sentences, designed to evaluate natural language inference models. It consists of premise-hypothesis pairs labeled as either entailment or neutral.
Name: QNLI
Date: 2018
Source: NYU, UWash, DeepMind
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Question Natural Language Inference (QNLI) dataset is derived from the Stanford Question Answering Dataset (SQuAD), where the task is to determine if a given sentence contains the answer to a question. It is used to train and evaluate models on question-answer entailment.
Name: MNLI
Date: 2018
Source: NYU
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Multi-Genre Natural Language Inference (MNLI) dataset consists of sentence pairs from a variety of sources, labeled for entailment, contradiction, or neutral relationships. It is designed to evaluate model performance across different genres of text.
Name: SNLI
Date: 2015
Source: Stanford
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Stanford Natural Language Inference (SNLI) dataset is a large collection of sentence pairs manually labeled for balanced classification with entailment, contradiction, and neutral categories. It is widely used for training and evaluating natural language understanding systems.
Name: RTE
Date: 2009
Source: FBK, CIU, NIST, CELCT
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The RTE-5 dataset is part of the Fifth PASCAL Recognizing Textual Entailment Challenge, containing pairs of text and hypothesis labeled as entailment or non-entailment. This dataset is used to evaluate models' abilities to determine if one sentence logically follows from another.
Name: Semantic Similarity
Date: 0
Source: nan
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: Semantic similarity refers to the degree of relatedness or similarity between two pieces of text based on their meaning. It involves quantifying the similarity of words, phrases, sentences, or documents using various techniques such as word embeddings, semantic models, or similarity metrics.
Name: QQP
Date: 2019
Source: NYU
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Quora Question Pairs (QQP) dataset contains pairs of questions from Quora labeled to indicate if they have the same intent or are semantically equivalent. It is used to train models for identifying duplicate questions.
Name: STS-B
Date: 2017
Source: Google, WashU, UBasque Country, USheffield
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Semantic Textual Similarity Benchmark (STSB) dataset from SemEval-2017, created by Google, contains sentence pairs annotated with similarity scores on a scale from 0 to 5. This dataset is used to train and evaluate models on their ability to predict the degree of semantic similarity between sentences.
Name: MRPC
Date: 2005
Source: Microsoft
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Microsoft Research Paraphrase (MSRP) dataset consists of pairs of sentences, each annotated to indicate whether they are semantically equivalent (paraphrases) or not. It is used to train and test models for paraphrase detection and semantic similarity tasks.
Name: Text Classification
Date: 0
Source: nan
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: Text classification is the task of categorizing text documents into predefined classes or categories based on their content. It is a fundamental problem in natural language processing and involves training models to automatically assign labels to text data, such as sentiment analysis, topic classification, or spam detection.
Name: CoLA
Date: 2014
Source: NYU, FAIR
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Corpus of Linguistic Acceptability (CoLA) consists of English sentences annotated for grammatical acceptability, based on the judgments of expert linguists. It is used to evaluate models on their ability to distinguish between grammatically correct and incorrect sentences.
Name: SST-2
Date: 2013
Source: Stanford
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Stanford Sentiment Treebank (SST) dataset includes movie reviews annotated with sentiment labels ranging from very negative to very positive. It is commonly used for training and evaluating sentiment analysis models.
Name: GPT-2
Date: 2019
Source: OpenAI
Talent Level: L3
Tech Type: AI/ML
Tech Source: Industry
Summary: A scaled-up version of GPT with 1.5 billion parameters, showing significant improvements in text generation quality and diversity compared to its predecessor. This advancement demonstrated the potential of increasing model size for performance gains in NLP tasks.
Name: Pre-training
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Pre-training involves training a model on a vast corpus of text data to learn general language patterns and representations. This foundational training enables the model to perform well on a variety of tasks after further fine-tuning on more specific datasets.
Name: WebText
Date: 2017
Source: Common Crawl
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The WebText dataset is a large-scale dataset introduced by OpenAI for training language models. It is comprised of a diverse range of internet text.
Name: DragNet
Date: 2013
Source: nan
Talent Level: L3
Tech Type: Others
Tech Source: Industry
Summary: The Dragnet dataset is a collection of web pages designed for evaluating algorithms that extract main content from web pages, omitting ads, navigation, and other extraneous elements. It provides labeled examples to facilitate the development and benchmarking of content extraction methods, ensuring algorithms can accurately identify and isolate the primary content from various types of web pages.
Name: Newspaper Content Text
Date: 0
Source: nan
Talent Level: L3
Tech Type: Others
Tech Source: Industry
Summary: The Newspaper Content Text dataset is a compilation of data gathered from newspaper articles. The dataset may\ include various features such as the title of the article, author, publication date, the content of the article, and\ more.
Name: Reddit
Date: 2005
Source: Reddit
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The Reddit dataset is a large collection of data from the social media platform, Reddit. It includes informa\ tion about Reddit posts, comments, upvotes, downvotes, and other user interactions on the site.
Name: Common Crawl
Date: 2018
Source: Common Crawl
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The Common Crawl dataset is a large and regularly updated corpus of web crawl data that is freely available \ to anyone. This dataset contains raw web page data, metadata, and text.
Name: Multitask Learning
Date: 1997
Source: CMU
Talent Level: L3
Tech Type: AI/ML
Tech Source: Academic
Summary: Multitask learning is an approach where a single model is trained to perform multiple related tasks simultaneously. By sharing information and features across tasks, multitask learning aims to improve the performance of individual tasks through joint learning, leading to better generalization and efficiency.
Name: Meta Learning
Date: 0
Source: nan
Talent Level: L3
Tech Type: AI/ML
Tech Source: Academic
Summary: Meta-learning, also known as learning to learn, involves training models on a variety of tasks with the goal of enabling them to quickly adapt to new tasks or domains with minimal data. It explores techniques for learning effective learning strategies or representations that generalize across tasks.
Name: Zero Shot
Date: 0
Source: nan
Talent Level: L3
Tech Type: AI/ML
Tech Source: Academic
Summary: Zero-shot learning is a machine learning paradigm where a model is trained to recognize classes it has never seen before during training. It involves learning to generalize to new classes by leveraging auxiliary information or semantic embeddings.
Name: MAML
Date: 2017
Source: Berkeley, OpenAI
Talent Level: L3
Tech Type: AI/ML
Tech Source: Academic
Summary: Model-Agnostic Meta-Learning (MAML) is a meta-learning algorithm that aims to train models to adapt quickly to new tasks with minimal data. It involves learning a good initialization that can be fine-tuned efficiently for new tasks, facilitating rapid adaptation.
Name: MQAN
Date: 2018
Source: Salesforce
Talent Level: L3
Tech Type: AI/ML
Tech Source: Industry
Summary: Multi-Question Answering Network (MQAN) is a neural network architecture designed for multi-hop question answering tasks. It enables the model to reason over multiple pieces of evidence to generate accurate answers to complex questions.
Name: decaNLP
Date: 2018
Source: Salesforce
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: decaNLP is a framework for training and evaluating multitask models across ten diverse natural language processing tasks. It covers a wide range of NLP tasks, including translation, summarization, and question answering, aiming to encourage research in multitask learning and generalization.
Name: QA-SRL
Date: 2015
Source: UWash
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: Question Answering-Semantic Role Labeling (QA-SRL) is a task that involves identifying semantic roles in sentences and generating answers based on these roles. It combines the tasks of question answering and semantic role labeling to improve natural language understanding.
Name: QA-ZRE
Date: 2017
Source: AllenAI
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: Question Answering-Zero-shot Relation Extraction (QA-ZRE) is a task that combines question answering and relation extraction, where models are trained to answer questions about relations between entities in text without explicit supervision for relation extraction.
Name: WOZ
Date: 2016
Source: Cambridge
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: Wizard-of-Oz (WOZ) is a data collection technique where human operators simulate the behavior of an automated system to collect naturalistic interactions with users. It is commonly used to gather training data for dialogue systems and conversational agents.
Name: WikiSQL
Date: 2017
Source: Salesforce
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: WikiSQL is a dataset for semantic parsing and question answering tasks, where models are trained to map natural language questions to SQL queries over a structured table. It is used to evaluate models on their ability to understand and generate SQL queries from text.
Name: Catastrophic forgetting
Date: 2019
Source: DeepMind
Talent Level: L3
Tech Type: AI/ML
Tech Source: Industry
Summary: Catastrophic forgetting refers to the phenomenon where a machine learning model forgets previously learned information when trained on new data. It is a challenge in lifelong or continual learning settings where models need to adapt to new tasks while retaining knowledge from previous tasks.
Name: Training Curriculum
Date: 2019
Source: DeepMind
Talent Level: L3
Tech Type: AI/ML
Tech Source: Industry
Summary: Training curriculum refers to a strategy for training machine learning models where training examples are presented to the model in a structured order, typically starting with simpler examples and gradually increasing in complexity. It is used to facilitate learning and improve the generalization performance of models.
Name: Tokenization
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Tokenization is the process of breaking down a text into smaller units, such as words, subwords, or characters, known as tokens. It is a crucial preprocessing step in natural language processing tasks, enabling the representation of text data in a format suitable for machine learning algorithms.
Name: BPE with Unicode
Date: 2019
Source: OpenAI
Talent Level: L3
Tech Type: Others
Tech Source: Industry
Summary: Byte Pair Encoding (BPE) with Unicode is an extension of the BPE algorithm that handles Unicode characters, allowing for the efficient tokenization of multilingual text. It is commonly used in natural language processing tasks such as machine translation and text generation.
Name: Unicode
Date: 1991
Source: Unicode Consortium
Talent Level: L1
Tech Type: Data
Tech Source: Academic
Summary: Unicode 1991 refers to the first version of the Unicode Standard published by the Unicode Consortium in 1991. It laid the foundation for character encoding and representation standards used in modern computing systems, facilitating the consistent handling of text across different platforms and languages.
Name: Fine-tuning
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Fine-tuning is a transfer learning technique where a pre-trained model is further trained on a specific task or domain with task-specific data. It involves updating the parameters of the pre-trained model using a smaller dataset, allowing the model to adapt to the nuances of the target task while leveraging the knowledge learned from the pre-training phase.
Name: GLUE
Date: 2018
Source: NYU, UWash, DeepMind
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: The General Language Understanding Evaluation (GLUE) benchmark is a collection of diverse natural language understanding tasks, including sentiment analysis, textual entailment, and question answering. It serves as a standard for evaluating and comparing the performance of language models.
Name: Natural Q
Date: 2019
Source: Google
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The Natural Questions dataset contains real anonymized questions from Google search, each paired with a Wikipedia page and a corresponding answer span. It is used to train and evaluate question answering systems on their ability to find precise answers within long documents.
Name: CoQA
Date: 2018
Source: Stanford
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: The Conversational Question Answering (CoQA) dataset consists of question-answer pairs within a conversational context, focusing on answering questions based on a given passage. It evaluates models on their ability to understand and generate contextually relevant answers in a conversation.
Name: LAMBADA
Date: 2016
Source: UTrento, UAmsterdam
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: The LAMBADA dataset is designed to test language models on their ability to predict the last word of sentences that require a broad understanding of the context provided by preceding text. It emphasizes the need for models to grasp long-range dependencies in text.
Name: WikiText
Date: 2016
Source: Salesforce
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The WikiText dataset is a collection of Wikipedia articles curated for language modeling tasks, featuring long-form, coherent text with minimal editing. It is used to train and evaluate models on their ability to generate and predict natural language text.
Name: CBT
Date: 2015
Source: FAIR
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The Children's Book Test (CBT) dataset, created by Facebook AI Research (FAIR), consists of sentences from children's books with one word removed and multiple-choice options provided for the missing word. It is designed to evaluate language models on their ability to understand and predict the context of a given text.
Name: CNN/Daily News
Date: 2015
Source: Google
Talent Level: L3
Tech Type: Data
Tech Source: Industry
Summary: The CNN/Daily Mail dataset is a large collection of news articles paired with multi-sentence summaries, created to facilitate research in automatic summarization and reading comprehension. It is used to train models to generate concise summaries from longer texts.
Name: 1BW
Date: 2013
Source: Google
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: The 1 Billion Word Benchmark is a dataset composed of a large collection of sentences from news articles, designed to support research in language modeling. It aims to evaluate models on their ability to predict and generate fluent and coherent text.
Name: PTB
Date: 1992
Source: UPenn, NorthwesternU
Talent Level: L3
Tech Type: Data
Tech Source: Academic
Summary: The Penn Treebank (PTB) dataset contains text from the Wall Street Journal, annotated with syntactic structure and part-of-speech tags. It is a standard benchmark for evaluating models on tasks such as syntactic parsing and language modeling.
Name: GPT-3
Date: 2021
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Announced by OpenAI, it boasts significantly more parameters than GPT-2 and showcases even more impressive capabilities in text generation, translation, and code writing. There is no official research paper, but announcements suggest GPT-3 is a significant leap forward in NLP capabilities.
Name: Pre-training
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Pre-training involves training a model on a vast corpus of text data to learn general language patterns and representations. This foundational training enables the model to perform well on a variety of tasks after further fine-tuning on more specific datasets.
Name: Filtered WebText
Date: 2019
Source: Common Crawl
Talent Level: L4
Tech Type: Data
Tech Source: Industry
Summary: Filtered WebText is a curated dataset derived from the Common Crawl, a publicly available web archive. It involves filtering and preprocessing raw web data to remove low-quality or irrelevant content, resulting in a high-quality text corpus suitable for training language models. This process ensures that the dataset includes diverse and informative text from reliable sources, enhancing the training data's overall quality. Filtered WebText is used to train various natural language processing models, providing them with a rich and diverse set of examples that help improve their language understanding, generation capabilities, and performance across a range of tasks.
Name: Book1, Book2
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Book1 and Book2 are nternet-based books corporas, containing a random sampling of a small subset of all the public domain books that humanity has published and are available online
Name: WikiPedia
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: A large text dataset comprised of data pulled from Wikipedia, an online encyclopedia
Name: Large Batch Training
Date: 2018
Source: OpenAI
Talent Level: L4
Tech Type: Others
Tech Source: Industry
Summary: Large batch training involves using significantly larger batch sizes in training deep learning models to improve training efficiency and model performance. This approach leverages advanced optimization techniques and robust computational resources to accelerate the training process while maintaining or enhancing the accuracy and generalization capabilities of the models.
Name: Weight Decay
Date: 2017
Source: UFreiburg
Talent Level: L4
Tech Type: Others
Tech Source: Academic
Summary: Weight Decay is a regularization technique used in training neural networks to prevent overfitting by penalizing large weights. As detailed in the paper "Decoupled Weight Decay Regularization," this method involves adding a term to the loss function that is proportional to the sum of the squared weights of the model. By doing so, the training process encourages the model to keep its weights small, which helps in reducing the model's complexity and improving generalization to unseen data. Decoupled weight decay specifically separates the weight decay from the gradient update step, allowing for more flexible and effective regularization. This approach enhances the stability and performance of neural networks, particularly in large-scale and complex models.
Name: Few Shot LM
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: A Few-Shot Language Model can understand and generate human-like text based on a small sample of input data. It reduces the necessity for large amounts of training data and is capable of performing tasks like translation, question answering, and summarization after being trained on diverse internet text.
Name: Sparse Transformer
Date: 2019
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: A Sparse Transformer is a deep learning model that utilizes sparse attention mechanism, enabling it to efficiently process long sequences of data by focusing on relevant parts rather than the entire sequence. This makes it particularly useful for tasks involving large amounts of data like language translation, image recognition, and music synthesis.
Name: MAML
Date: 2017
Source: Berkeley, OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Academic
Summary: MAML (Model-Agnostic Meta-Learning) is a machine learning algorithm that aims to rapidly adapt to new tasks with minimal training data by learning a model initialization that can be fine-tuned effectively. It's model-agnostic in the sense that it can be applied to any model trained with gradient descent, making it highly versatile in application.
Name: Match Network
Date: 2016
Source: DeepMind
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: A Match Network is a digital infrastructure that facilitates the interconnection of various internet networks, often referred to as autonomous systems, to exchange internet traffic between them, thus improving speed, reliability, and cost-effectiveness. By utilizing the Border Gateway Protocol, it helps in routing and IP addressing, enabling seamless communication and data transfer across multiple networks.
Name: Parameter Scaling
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Parameter scaling, also known as feature scaling, is a data preprocessing technique used to standardize the range of independent variables or features of data. This process improves the performance and stability of machine learning algorithms, particularly those that use gradient descent as an optimization strategy.
Name: Scaling Law for NN
Date: 0
Source: OpenAI
Talent Level: L4
Tech Type: Others
Tech Source: Industry
Summary: Scaling laws for neural networks refer to the relationship between the resources used (such as data, model size, or training time) and the model's performance. Essentially, increasing these resources tend to improve the model's performance, but with diminishing returns, meaning that after a certain point, adding more resources leads to smal\ ler and smaller improvements.
Name: Few Shot Test
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Few Shot Test is a method in machine learning where a model is trained to identify a new category based on a few examples, thereby testing the model's ability to generalize from limited data. It's a crucial test for AI systems, mimicking the human ability to learn new concepts from a few instances.
Name: SuperGLUE
Date: 2019
Source: NYU, FAIR, UWash, DeepMind
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: SuperGLUE is a benchmark designed to be more challenging than GLUE, consisting of a diverse set of natural language understanding tasks including coreference resolution, commonsense reasoning, and question answering. It aims to push the boundaries of current language models.
Name: HellaSwag
Date: 2019
Source: AllenAI, UWash
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: HellaSwag is a dataset designed for commonsense reasoning, containing multiple-choice questions where models must choose the most plausible continuation of a given context. It focuses on evaluating the ability of models to generate and understand coherent, sensible text.
Name: WinoGrande
Date: 2019
Source: AllenAI, UWash
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: WinoGrande is a dataset for commonsense reasoning, derived from the Winograd Schema Challenge, containing sentence pairs with ambiguous pronouns that require commonsense knowledge to resolve. It is used to train and test models on their ability to understand context and resolve ambiguities.
Name: Natural Q
Date: 2019
Source: Google
Talent Level: L4
Tech Type: Data
Tech Source: Industry
Summary: The Natural Questions dataset contains real anonymized questions from Google search, each paired with a Wikipedia page and a corresponding answer span. It is used to train and evaluate question answering systems on their ability to find precise answers within long documents.
Name: DROP
Date: 2019
Source: UCI, PekingU, AllenAI, UWash
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: The Discrete Reasoning Over Paragraphs (DROP) dataset consists of questions that require discrete operations such as addition, subtraction, or sorting to answer, based on information within paragraphs. It evaluates the ability of models to perform complex reasoning over textual data.
Name: ARC
Date: 2018
Source: AllenAI
Talent Level: L4
Tech Type: Data
Tech Source: Industry
Summary: The AI2 Reasoning Challenge (ARC) dataset includes multiple-choice science questions from standardized exams, designed to test advanced reasoning abilities in artificial intelligence systems. It is used to evaluate models on their understanding of scientific concepts and reasoning skills.
Name: TriviaQA
Date: 2017
Source: AllenAI
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: TriviaQA is a large-scale question answering dataset containing question-answer pairs from trivia websites, with corresponding evidence documents from Wikipedia and the web. It is designed to train and evaluate models on their ability to find and extract relevant information.
Name: TriviaQA
Date: 2017
Source: AllenAI
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: TriviaQA is a large-scale question answering dataset containing question-answer pairs from trivia websites, with corresponding evidence documents from Wikipedia and the web. It is designed to train and evaluate models on their ability to find and extract relevant information.
Name: LAMBADA
Date: 2016
Source: UTrento, UAmsterdam
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: The LAMBADA dataset is designed to test language models on their ability to predict the last word of sentences that require a broad understanding of the context provided by preceding text. It emphasizes the need for models to grasp long-range dependencies in text.
Name: StoryCloze
Date: 2016
Source: URochester, USNA, VT, Microsoft
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: The StoryCloze Test is a dataset for evaluating story understanding and script learning, where models are given the beginning of a story and must choose the correct ending from two options. It assesses the ability of models to generate coherent and contextually appropriate narrative continuations.
Name: WebQ
Date: 2013
Source: Stanford
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: The WebQuestions (WebQ) dataset contains questions sourced from Google queries, paired with answers from Freebase, a large knowledge graph. It is used to evaluate models on their ability to understand and answer natural language questions based on structured data.
Name: PTB
Date: 1992
Source: UPenn, NorthwesternU
Talent Level: L2
Tech Type: Data
Tech Source: Academic
Summary: The Penn Treebank (PTB) dataset contains text from the Wall Street Journal, annotated with syntactic structure and part-of-speech tags. It is a standard benchmark for evaluating models on tasks such as syntactic parsing and language modeling.
Name: GPT-4
Date: 2023
Source: OpenAI
Talent Level: L5
Tech Type: AI/ML
Tech Source: Industry
Summary: Likely an even larger and more powerful version of GPT-3 under development at OpenAI. Details are unknown, but it is expected to continue the trend of improved performance with increasing model size.
Name: Training
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Training involves feeding a model large amounts of data and adjusting its parameters through iterative optimization to minimize the difference between its predictions and the actual outcomes. This process allows the model to learn patterns and relationships within the data, improving its ability to make accurate predictions or generate relevant outputs when given new inputs.
Name: Multimodal LM
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Multimodal machine learning models process information from multiple sources, like text, images, or audio. By combining these modalities, they gain a richer understanding of the data compared to models using a single data type. This allows them to perform tasks like generating captions for images or translating spoken language while considering visual context.
Name: RLHF
Date: 2023
Source: OpenAI
Talent Level: L5
Tech Type: AI/ML
Tech Source: Industry
Summary: RLHF stands for Reinforcement Learning from Human Feedback. It's a technique used to improve the model by giving it rewards based on human input.
Name: MoE
Date: 2017
Source: Google, JagiellonianU
Talent Level: L5
Tech Type: AI/ML
Tech Source: Industry
Summary: MoE has many smaller, specialized networks ("experts") and a gating network. The gating network selects a few experts for each input, allowing the MoE layer to handle complex tasks with thousands of times more parameters than usual.
Name: Red Teaming
Date: 2022
Source: DeepMind, NYU
Talent Level: L5
Tech Type: AI/ML
Tech Source: Collaborative
Summary: Red Teaming is a project at DeepMind aimed at developing AI systems capable of strategic reasoning and planning in complex adversarial environments. It focuses on creating agents that can anticipate and counteract the actions of adversaries through game-theoretic approaches.
Name: Sparrow
Date: 2022
Source: DeepMind
Talent Level: L5
Tech Type: AI/ML
Tech Source: Industry
Summary: Sparrow is a research project by DeepMind focusing on developing techniques for self-supervised reinforcement learning. It aims to enable agents to learn effective behavior from their own experiences without requiring external supervision.
Name: Test Data
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Test data is a separate subset of data used to evaluate the performance of a trained model, ensuring it can generalize well to unseen examples. It provides an unbiased measure of the model's accuracy and effectiveness by comparing its predictions against known outcomes not previously seen during training.
Name: MMLU
Date: 2020
Source: Berkeley, Columbia
Talent Level: L5
Tech Type: Data
Tech Source: Academic
Summary: The Massive Multitask Language Understanding (MMLU) dataset includes a wide range of multiple-choice questions across various domains such as history, mathematics, and science. It is designed to evaluate the breadth and depth of a language model's general knowledge and reasoning abilities.
Name: HumanEval
Date: 2021
Source: OpenAI
Talent Level: L5
Tech Type: Data
Tech Source: Industry
Summary: The HumanEval dataset consists of programming problems designed to assess the code generation capabilities of language models. Each problem includes a natural language prompt and a set of test cases, used to evaluate the correctness and functionality of generated code.
Name: GSM-8K
Date: 2021
Source: OpenAI
Talent Level: L5
Tech Type: Data
Tech Source: Industry
Summary: The Grade School Math 8K (GSM-8K) dataset contains thousands of math word problems typically encountered in grade school. It is used to train and evaluate models on their ability to perform arithmetic and understand mathematical concepts in a natural language context.
Name: ETHICS
Date: 2020
Source: Berkeley, Columbia
Talent Level: L5
Tech Type: Data
Tech Source: Academic
Summary: The ETHICS dataset is designed to evaluate the ethical reasoning abilities of AI models. It includes scenarios and questions related to moral and ethical dilemmas, aiming to train and assess models on their understanding and application of ethical principles.
Name: TruthfulQA
Date: 2021
Source: UOxford, OpenAI
Talent Level: L4
Tech Type: Data
Tech Source: Collaborative
Summary: TruthfulQA is a dataset designed to evaluate the truthfulness and factual accuracy of language models when answering questions. It includes questions that are carefully crafted to test whether models produce truthful responses, addressing the challenge of misinformation in AI-generated content.
Name: RealToxicityPrompts
Date: 2020
Source: AllenAI
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: RealToxicityPrompts is a dataset created to study and mitigate the generation of toxic language by AI models. It consists of prompts that could lead to toxic completions, used to evaluate and improve the safety and robustness of language models against generating harmful content.
Name: HellaSwag
Date: 2019
Source: AllenAI, UWash
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: HellaSwag is a dataset designed for commonsense reasoning, containing multiple-choice questions where models must choose the most plausible continuation of a given context. It focuses on evaluating the ability of models to generate and understand coherent, sensible text.
Name: WinoGrande
Date: 2019
Source: AllenAI, UWash
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: WinoGrande is a dataset for commonsense reasoning, derived from the Winograd Schema Challenge, containing sentence pairs with ambiguous pronouns that require commonsense knowledge to resolve. It is used to train and test models on their ability to understand context and resolve ambiguities.
Name: DROP
Date: 2019
Source: UCI, PekingU, AllenAI, UWash
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: The Discrete Reasoning Over Paragraphs (DROP) dataset consists of questions that require discrete operations such as addition, subtraction, or sorting to answer, based on information within paragraphs. It evaluates the ability of models to perform complex reasoning over textual data.
Name: ARC
Date: 2018
Source: AllenAI
Talent Level: L4
Tech Type: Data
Tech Source: Industry
Summary: The AI2 Reasoning Challenge (ARC) dataset includes multiple-choice science questions from standardized exams, designed to test advanced reasoning abilities in artificial intelligence systems. It is used to evaluate models on their understanding of scientific concepts and reasoning skills.
Name: InstructGPT
Date: 2022
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Built upon GPT-3, InstructGPT is fine-tuned with human instruction and reinforcement learning for better adherence to instructions and factual grounding in responses. This addresses some of the limitations of large language models, such as potential biases and factual inaccuracies.
Name: Training
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: Training involves feeding a model large amounts of data and adjusting its parameters through iterative optimization to minimize the difference between its predictions and the actual outcomes. This process allows the model to learn patterns and relationships within the data, improving its ability to make accurate predictions or generate relevant outputs when given new inputs.
Name: RLHF
Date: 2017
Source: DeepMind, OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: RLHF (Reinforcement Learning from Human Feedback) is a method that combines reinforcement learning with human preferences to train AI models more effectively. Detailed in the paper "Deep Reinforcement Learning from Human Preferences," this approach involves using human feedback to guide the training process, allowing the model to learn behaviors that align with human values and expectations. By incorporating human input into the reward function, RLHF improves the model's performance on tasks where purely algorithmic rewards might be insufficient or misaligned with desired outcomes. This method is particularly useful in applications requiring complex decision-making and nuanced understanding, such as robotics, game playing, and interactive AI systems.
Name: Alignment Tax
Date: 2018
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Alignment Tax refers to the performance trade-off incurred when aligning a language model's behavior with human values and expectations. Introduced in the context of the paper "Improving Language Understanding by Generative Pre-Training," this concept highlights the potential reduction in a model's raw performance or efficiency due to the additional constraints and modifications necessary to ensure its outputs are aligned with desired ethical standards and user preferences. The "tax" is the cost of achieving more responsible and user-friendly AI behavior, balancing the pursuit of accuracy and robustness with the need for alignment in real-world applications.
Name: Agent Alignment
Date: 2018
Source: DeepMind
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Agent Alignment is the process of ensuring that an artificial intelligence (AI) system's actions and goals are in line with human values and intentions. As discussed in the paper "Scalable Agent Alignment via Reward Modeling: A Research Direction," this involves designing and training AI agents so that their behavior consistently meets the expectations and requirements of human users. One approach to achieving agent alignment is through reward modeling, where human feedback is used to shape the reward functions that guide the AI's learning and decision-making processes. This research direction aims to develop scalable methods to align increasingly complex AI systems with human values, ensuring their safe and beneficial deployment in real-world scenarios.
Name: PPO
Date: 2017
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Proximal Policy Optimization (PPO) is a type of reinforcement learning algorithm introduced by OpenAI in the paper "Proximal Policy Optimization Algorithms." PPO strikes a balance between simplicity and performance, making it a widely used approach for training AI agents. It improves upon previous policy gradient methods by using a novel objective function that prevents large, destabilizing updates to the policy, ensuring more stable and reliable learning. PPO employs a clipped surrogate objective to limit the change in the policy at each training step, which helps maintain the balance between exploration and exploitation. This approach has shown strong empirical performance across various domains, including robotics, game playing, and other complex decision-making tasks.
Name: RLHF
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: RLHF (Reinforcement Learning from Human Feedback) is a method that combines reinforcement learning with human preferences to train AI models more effectively. Detailed in the paper "Deep Reinforcement Learning from Human Preferences," this approach involves using human feedback to guide the training process, allowing the model to learn behaviors that align with human values and expectations. By incorporating human input into the reward function, RLHF improves the model's performance on tasks where purely algorithmic rewards might be insufficient or misaligned with desired outcomes. This method is particularly useful in applications requiring complex decision-making and nuanced understanding, such as robotics, game playing, and interactive AI systems.
Name: Value-aligned RL
Date: 2021
Source: Kentucky U
Talent Level: L4
Tech Type: AI/ML
Tech Source: Academic
Summary: Value-aligned Reinforcement Learning (RL) is a methodology that aims to train AI agents whose actions and policies are aligned with human values and societal norms. Detailed in the paper "Training Value-Aligned Reinforcement Learning Agents Using a Normative," this approach involves incorporating ethical guidelines and normative principles into the RL training process. By using reward functions that reflect human values, along with human feedback and normative data, value-aligned RL seeks to ensure that the resulting agents behave in ways that are consistent with desired moral and ethical standards. This field is critical for the development of AI systems that are safe, trustworthy, and beneficial for society.
Name: EXT5/EXMIX
Date: 2021
Source: Google
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: ExT5 (Extreme T5) and ExMIX are advanced models introduced in the paper "ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning." These models extend the T5 (Text-to-Text Transfer Transformer) framework by scaling it to handle a vast number of tasks simultaneously, leveraging multi-task learning to improve generalization and performance across diverse NLP tasks. ExT5 utilizes an extreme multi-task mixture (ExMIX), where the model is trained on a highly diverse set of tasks, allowing it to learn shared representations and transfer knowledge more effectively. This approach aims to push the boundaries of transfer learning, demonstrating that with sufficient scaling and task diversity, models can achieve superior performance on a wide range of benchmarks, from text generation and translation to comprehension and summarization.
Name: Cross Talk Gen
Date: 2021
Source: AllenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Cross-Talk Gen is a framework introduced in the paper "Cross-Task Generalization via Natural Language Crowdsourcing Instructions." It focuses on enhancing the generalization capabilities of AI models across different tasks by utilizing natural language instructions collected from crowdsourcing. This approach leverages diverse human-provided instructions to train models that can understand and perform a wide variety of tasks, even those they have not been explicitly trained on. By generalizing from these instructions, Cross-Talk Gen aims to create more flexible and adaptable models capable of transferring knowledge between tasks. This method demonstrates the potential of using natural language as a universal medium for task specification, significantly improving the versatility and robustness of AI systems.
Name: UnifiedQA
Date: 2021
Source: AllenAI, UWash
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: UnifiedQA is a question-answering system introduced in the paper "UnifiedQA: Crossing Format Boundaries With a Single QA System." This model is designed to handle multiple types of question-answering formats within a single framework, including extractive QA, abstractive QA, multiple-choice QA, and yes/no questions. UnifiedQA is built on top of T5 (Text-to-Text Transfer Transformer) and leverages the text-to-text paradigm to unify various QA tasks. By training on a diverse set of question-answering datasets, UnifiedQA can generalize across different formats and domains, providing accurate and coherent answers. This approach simplifies the development of QA systems and demonstrates robust performance across a wide range of benchmarks, highlighting its versatility and effectiveness in natural language understanding and generation.
Name: Recursive sum with HF
Date: 2021
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Recursive Summarization with Human Feedback (HF) is a technique outlined in the paper "Recursively Summarizing Books with Human Feedback." This approach involves generating summaries of large texts, such as books, through a recursive process that incrementally condenses information. Human feedback is incorporated at various stages to ensure the accuracy, coherence, and relevance of the summaries. By iteratively summarizing smaller sections and refining them based on human input, this method aims to produce high-quality summaries that capture the essential content and meaning of the original text. The combination of recursive summarization and human feedback enhances the model's ability to handle complex and lengthy documents, making it a valuable tool for efficient information extraction and content comprehension.
Name: Rank Preference Model
Date: 2021
Source: Anthropic
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: The Rank Preference Model is introduced in the context of the paper "A General Language Assistant as a Laboratory for Alignment." This model is designed to align AI behaviors with human preferences by ranking multiple outputs based on human feedback. Instead of relying solely on numerical reward signals, the Rank Preference Model incorporates direct human judgments about which outputs are better. This approach helps in fine-tuning AI systems to generate responses that are more aligned with human values and expectations. By systematically ranking outputs and learning from these preferences, the model improves its ability to produce desirable and appropriate responses, enhancing its alignment with human users and improving its performance in various applications.
Name: Summary from HF
Date: 2020
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: "Summary from Human Feedback" is a technique detailed in the paper "Learning to Summarize from Human Feedback." This method leverages human evaluations to improve the quality of automated text summaries. Instead of relying solely on predefined metrics, the model receives feedback from humans on the generated summaries, learning to produce more accurate, coherent, and relevant content. This iterative process involves presenting summaries to human reviewers, who then provide feedback used to refine the model's future outputs. By incorporating human judgment, the approach enhances the summarization model's ability to understand and prioritize the most critical information, leading to higher quality and more user-aligned summaries.
Name: Summary from HF
Date: 2019
Source: Darmstadt U
Talent Level: L4
Tech Type: AI/ML
Tech Source: Academic
Summary: "Summary from Human Feedback (HF)" is a method outlined in the paper "Better Rewards Yield Better Summaries: Learning to Summarise Without Human-Written Summaries." This approach focuses on improving the quality of machine-generated summaries by utilizing human feedback instead of relying solely on human-written summaries as references. The model is trained to optimize for rewards based on human evaluations, which assess the relevance, coherence, and informativeness of the generated summaries. By directly incorporating human preferences into the reward structure, this method enables the summarization model to learn more effectively, producing high-quality summaries that better align with human expectations and needs.
Name: LaMDA
Date: 2022
Source: Google
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: LaMDA (Language Models for Dialog Applications) is a conversational AI model developed by Google, as described in the paper "LaMDA: Language Models for Dialog Applications." LaMDA is designed to generate natural and engaging dialogue across a wide range of topics. Unlike traditional language models, LaMDA focuses specifically on dialogue applications, emphasizing the ability to maintain context, provide informative responses, and exhibit open-ended conversational capabilities. It leverages advanced machine learning techniques to understand the nuances of human language and generate responses that are contextually appropriate and coherent. LaMDA aims to improve the quality of human-computer interactions, making them more seamless and natural.
Name: Dialog Model
Date: 2019
Source: CalTech, Google
Talent Level: L4
Tech Type: AI/ML
Tech Source: Collaborative
Summary: The Dialog Model discussed in the paper "Towards Coherent and Engaging Spoken Dialog Response Generation Using" focuses on improving the generation of responses in spoken dialogues. This model aims to create more coherent, contextually appropriate, and engaging interactions between humans and AI systems. It employs advanced natural language processing techniques to understand the context and nuances of a conversation, enabling it to generate responses that are not only accurate but also engaging and natural. The goal of this model is to enhance the overall quality of human-computer interactions, making them more fluid and human-like, and to address common challenges in dialogue systems such as maintaining context and handling diverse conversational topics.
Name: Reward Learning
Date: 2019
Source: OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Reward Learning, as detailed in the paper "Fine-Tuning Language Models from Human Preferences," is a technique used to enhance language models by incorporating human feedback into their training process. This method involves using human evaluations to shape the reward function, guiding the model to generate outputs that align more closely with human values and preferences. By fine-tuning the model based on human-provided feedback, Reward Learning helps the model learn which responses are more appropriate, relevant, and useful. This approach aims to improve the overall quality and alignment of language models, making them more effective and reliable in generating human-like and contextually suitable responses.
Name: Reward Model
Date: 2018
Source: Montreal U
Talent Level: L4
Tech Type: AI/ML
Tech Source: Academic
Summary: The Reward Model, as discussed in the paper "Learning to Understand Goal Specifications by Modelling Reward," is a framework used to train AI systems to comprehend and achieve specified goals by modeling rewards. This approach involves defining a reward function that captures the desired outcomes and behaviors, allowing the AI to learn which actions lead to achieving these goals. By simulating and optimizing for these rewards during training, the model can better understand and fulfill complex goal specifications. The Reward Model is particularly useful in reinforcement learning, where it helps align the AI's actions with the intended objectives, leading to more effective and goal-oriented behavior in various applications.
Name: Reward Function
Date: 2018
Source: Google, OpenAI
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: The Reward Function, as outlined in the paper "Reward Learning from Human Preferences and Demonstrations in Atari," is a crucial component in reinforcement learning systems that defines the goals and desired outcomes for an AI agent. It assigns numerical values to different actions or sequences of actions, guiding the agent towards behaviors that maximize cumulative rewards. In this context, reward functions are learned from human preferences and demonstrations, providing a more intuitive and aligned basis for training. By incorporating human input, the reward function ensures that the agent's actions are not only optimal from a computational perspective but also aligned with human expectations and values. This approach enhances the agent's performance and reliability in complex tasks, such as playing Atari games, by leveraging both expert demonstrations and feedback.
Name: MoE
Date: 2021
Source: Google
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: MoE (Mixture of Experts), as presented in the paper "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity," is a model architecture designed to efficiently scale neural networks to massive sizes. MoE uses multiple expert subnetworks, where each expert is specialized for different parts of the input data. During training and inference, only a subset of these experts is activated, making the model computationally efficient despite its large size. The "Switch" mechanism dynamically routes input to the most relevant experts, improving both performance and scalability. This approach allows the creation of models with trillions of parameters while maintaining practical computational and memory requirements, achieving state-of-the-art results in various natural language processing tasks.
Name: Scaling LM
Date: 2021
Source: DeepMind
Talent Level: L4
Tech Type: AI/ML
Tech Source: Industry
Summary: Scaling Language Models, as explored in the paper "Scaling Language Models: Methods, Analysis & Insights from Training Gopher," refers to the practice of increasing the size and complexity of language models to improve their performance and capabilities. This process involves expanding the number of parameters, enhancing data quality and diversity, and optimizing training techniques to handle larger models. The paper provides an in-depth analysis of the benefits and challenges associated with scaling, such as improved accuracy, generalization, and the ability to perform a broader range of tasks. It also addresses potential issues like increased computational costs and the need for advanced hardware. The insights gained from training Gopher, a large-scale language model, contribute to the understanding of how to effectively scale models to achieve superior performance in natural language processing.
Name: Test Data
Date: 0
Source: nan
Talent Level: nan
Tech Type: nan
Tech Source: nan
Summary: nan
Name: FLAN
Date: 2021
Source: Google
Talent Level: L4
Tech Type: Data
Tech Source: Industry
Summary: The Fine-tuned Language Net (FLAN) dataset by Google involves instruction-based fine-tuning of language models to improve their ability to follow complex instructions and generate accurate, context-aware responses. It is used to enhance the performance of models in understanding and executing diverse tasks.
Name: T0
Date: 2021
Source: BrownU, Hugging Face, others
Talent Level: L4
Tech Type: Data
Tech Source: Collaborative
Summary: The T0 dataset is part of a project that uses prompted datasets to train models on a wide range of tasks using a unified natural language interface. It leverages prompt-based learning to improve model generalization across various natural language processing tasks.
Name: TruthfulQA
Date: 2021
Source: UOxford, OpenAI
Talent Level: L4
Tech Type: Data
Tech Source: Collaborative
Summary: TruthfulQA is a dataset designed to evaluate the truthfulness and factual accuracy of language models when answering questions. It includes questions that are carefully crafted to test whether models produce truthful responses, addressing the challenge of misinformation in AI-generated content.
Name: RealToxicityPrompts
Date: 2020
Source: AllenAI
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: RealToxicityPrompts is a dataset created to study and mitigate the generation of toxic language by AI models. It consists of prompts that could lead to toxic completions, used to evaluate and improve the safety and robustness of language models against generating harmful content.
Name: CrowS-Pairs
Date: 2020
Source: NYU
Talent Level: L4
Tech Type: Data
Tech Source: Academic
Summary: CrowS-Pairs is a dataset designed to measure and reduce social biases in AI language models. It includes sentence pairs that exhibit various types of social biases, such as race or gender bias, and is used to assess and improve the fairness and impartiality of language models.