

Tokenization
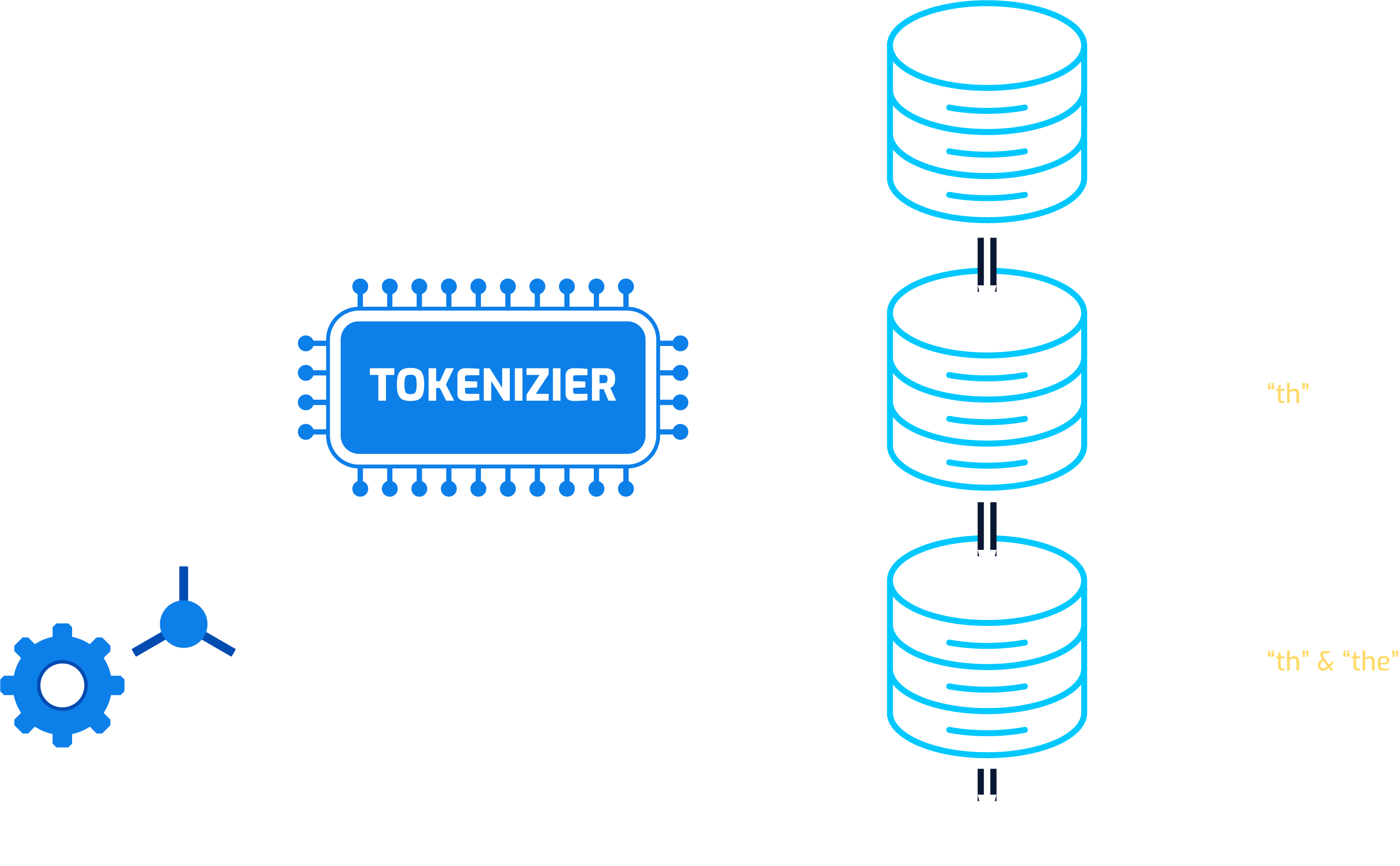
- To infinity and beyond => 1 token
- Hakuna Matata! => 1 token
- Bibbidi Bobbidi Boo => 1 token
- Circle of life => 1 token …
Text Summarization
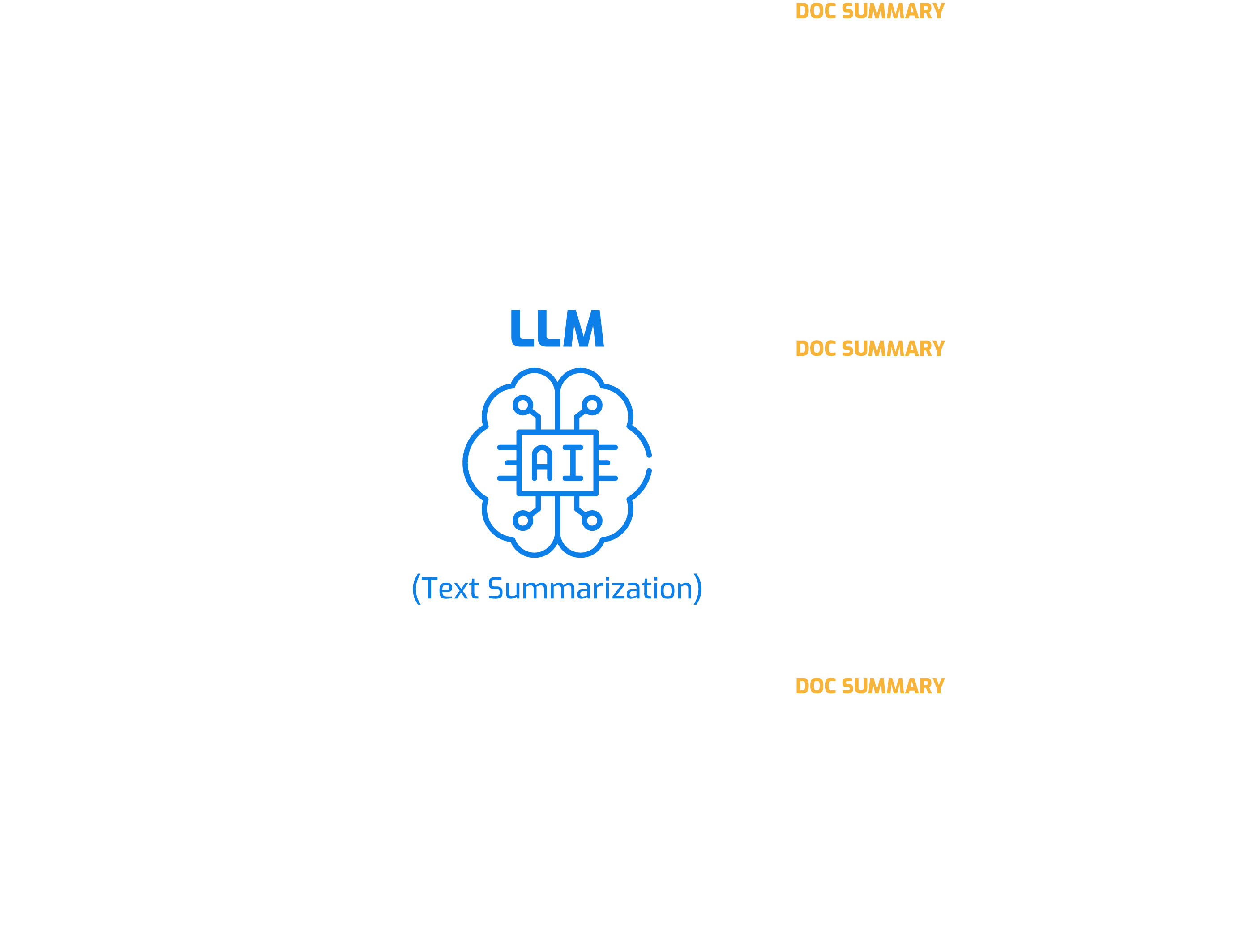
- Organize: By using the summary of a document as an index into the database, documents can be much better organized
- Search: When anyone needs to access any document, searching may become easier with the summary of documents
- Compare: The summary of documents can be used to compare documents much more easily to boost efficiency
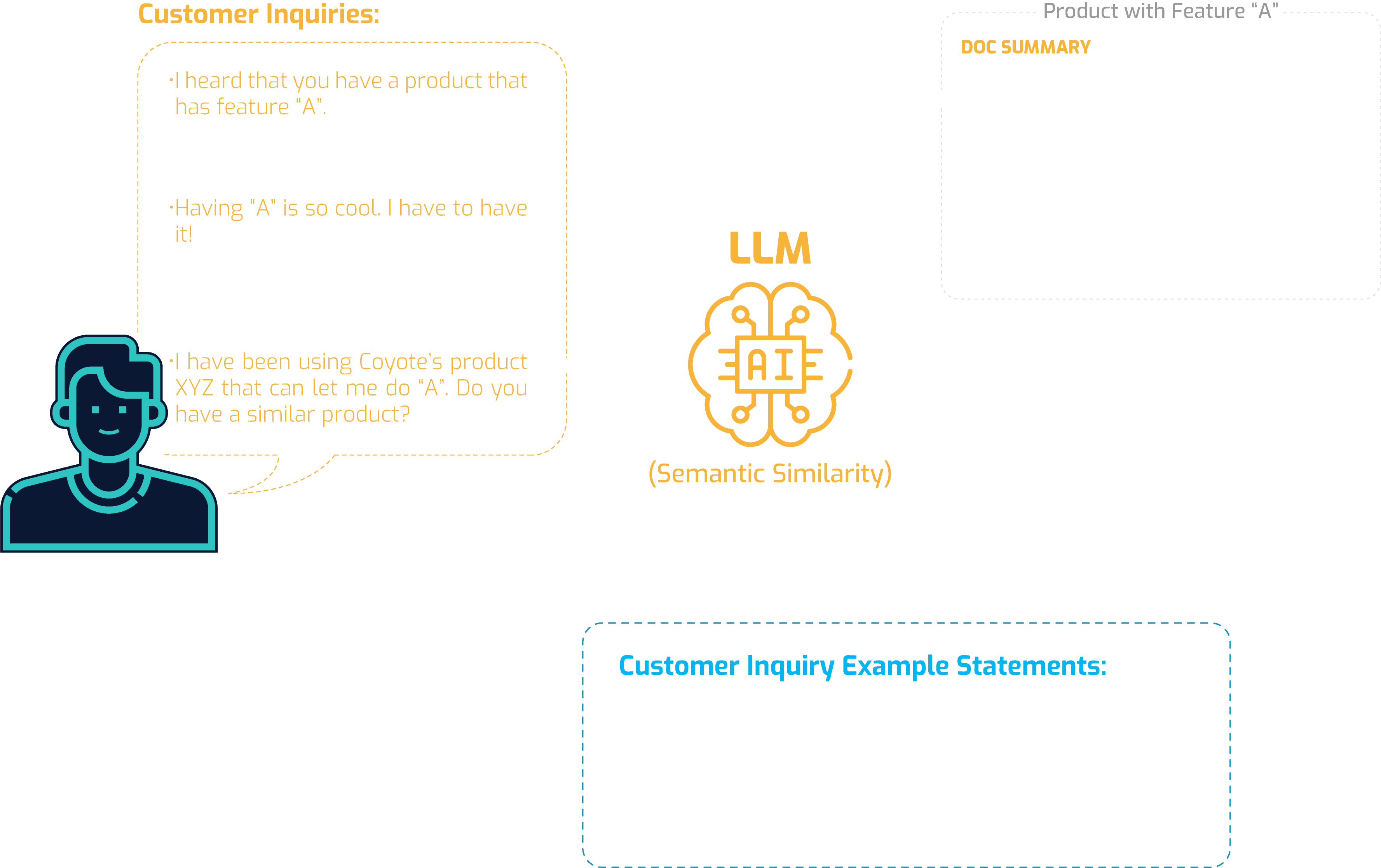
Semantic Similarity
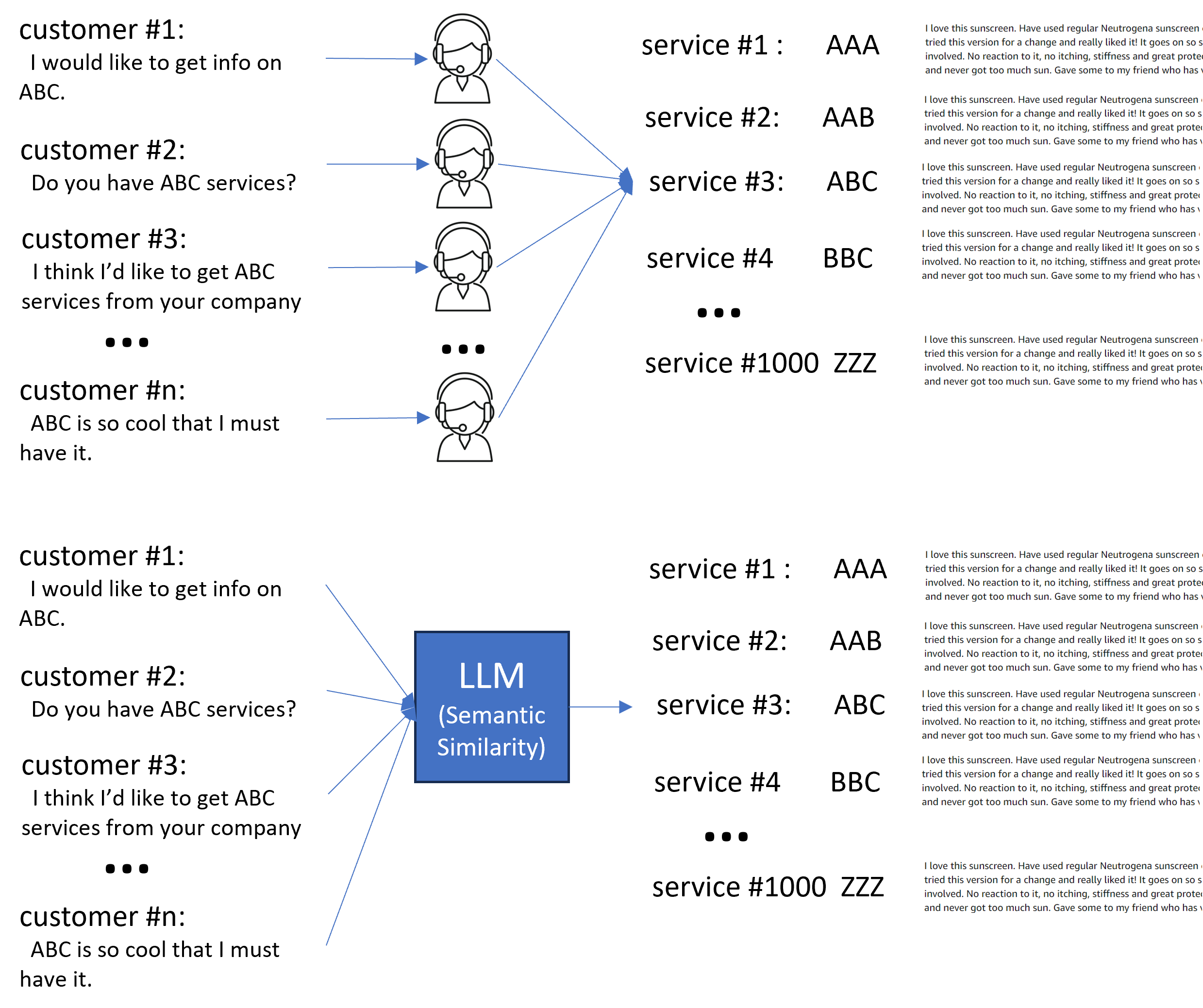
ACME’s ability to manage the language data efficiently through AI technology catapulted the enterprise to be one of the leaders in the industry boosting their sales and increasing the number of customers. Now they are getting over ten thousand calls a day from their current customers and prospective customers.
Because there are virtually infinite permutations of how natural language is spoken (the way customers ask about a product or services may differ widely from person to person even though the product or services may be the same), ACME Inc. hired and trained agents that are proficient in English to service their customers. Here is an example of how customers would inquire about products and services.
- I heard that you have a product that has feature “A”.
- I’d like to get information about a product with “A” ability.
- Having “A” is so cool. I have to have it!
- Can you tell me about specification of “A” and if there is any product that has it?
- I have been using Coyote’s product XYZ that can let me do “A”. Do you have a similar product?
But now they are inundated with customer calls that their agents are not able to respond fast enough. ACME’s AI team yet again steps into resolve the current crisis with another LLM’s feature called Semantic Similarity.
Semantic similarity refers to how similar two pieces of text are in meaning, even if the wording is different. It’s not just about identical or matching words, but rather the underlying concepts and ideas they convey.
Semantic similarity is crucial in natural language processing (NLP) tasks, as it helps algorithms understand the context and meaning of text beyond just individual words.
For each product, service, or information that ACME Inc. has, we will add few examples statements of how a customer (or employee) would describe the product, service, or info. Because we will be using the Semantic Similarity feature of the LLM, the few statements that we need to add do not have to be exhaustive which by the way if virtually impossible. We just need to add few representative statements that people can use to ask or describe each product, service, or info.
Question Answering
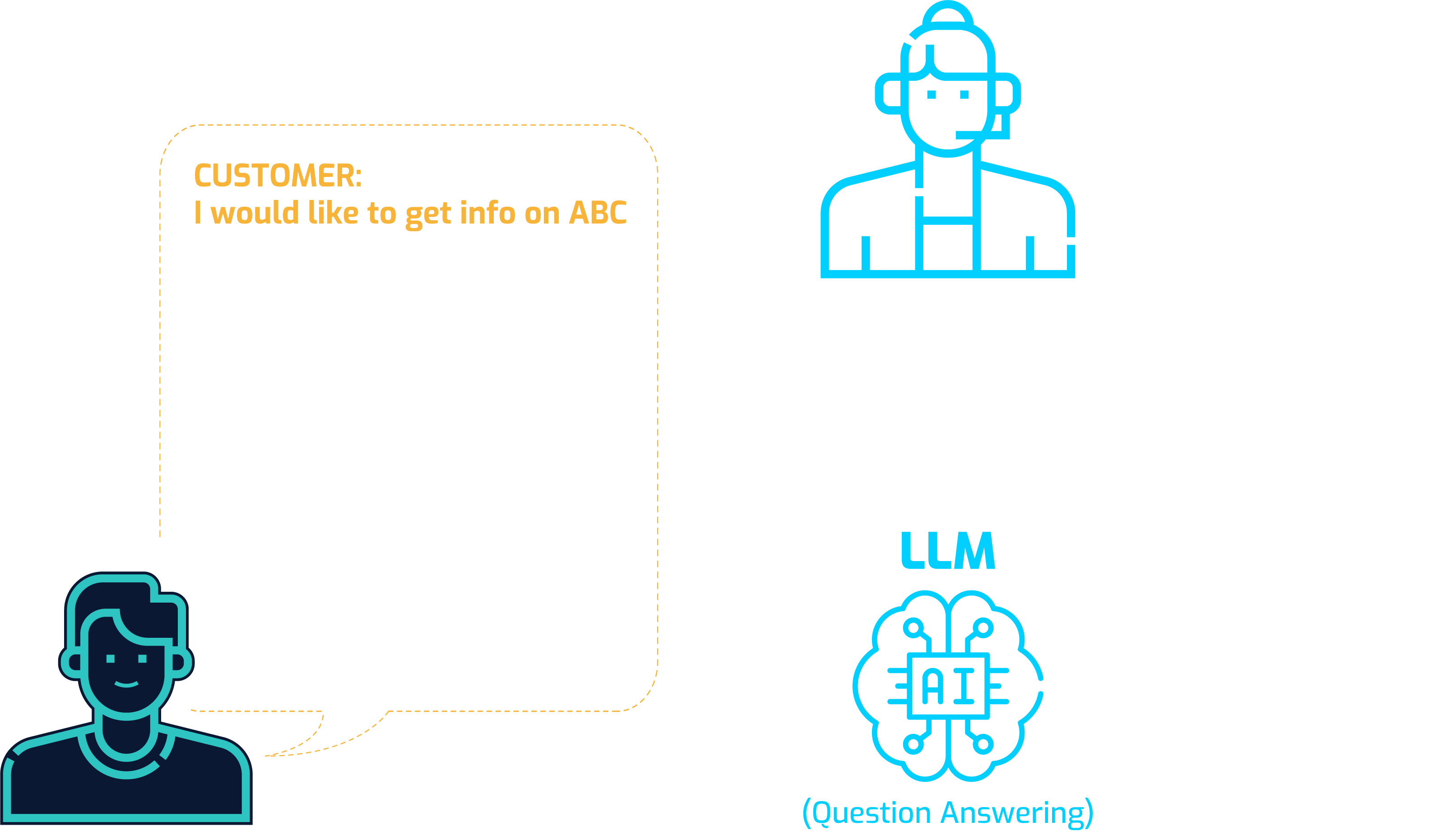
ACME’s various AI technologies and LLM features enable the enterprise’s customers and employees to access vast amount of language data automatically via natural language instructions/prompts. Given a natural language instruction, we can now retrieve the relevant documents or paragraphs in a document. Before customers commit to purchase a product or a service, there are typically questions to be asked and answered. There is another feature of LLM’s that can help with this process called Question Answering (QA).
Question answering (QA) is a branch of Artificial Intelligence (AI) that deals with automatically creating answers to questions posed in natural language. The goal is to develop systems that can understand the meaning of a question and retrieve or generate an accurate answer from a variety of sources, just like a human might do.
There are two main categories of question answering systems:
- Open Domain QA: These systems aim to answer a wide range of questions from any domain, similar to a search engine. They rely on vast amounts of text data and require advanced techniques to understand the context and intent of a question.
- Closed Domain QA: These systems are designed to answer questions within a specific domain, like customer service chatbots for a particular company. They typically have access to a well-defined knowledge base or dataset relevant to their domain, making answer retrieval more focused.
A typical closed-domain QA dataset is very similar to reading comprehension questions that many schools exams employ. One popular QA dataset is called SQuAD (Stanford Question Answering Dataset). There are three parts in SQuAD data set: a passage from Wikipedia, a question related to the passage, and the answer.

The passage and the question related to the passage becomes an input to the LLM model like ChatGPT, and the answer is the output/label which is the output ChatGPT is expected to generate. ChatGPT’s ability to answer questions based on a text depends on quality of these triplet QA dataset. The obvious scenario is that if someone asks ChatGPT questions that it was trained with, such as above example of the question regrading graupel, ChatGPT would answer correctly. But the less obvious scenario is that when ChatGPT is given a text that it has not seen during its training, and a person asks a question related to the text, can ChatGPT answer correctly? Well, it depends. If ChatGPT is trained with many permutations of text – permutation on vocabulary, sentence structure, content, ChatGPT can be “generalized” to answer questions on a text that it has not seen. Example is the following.

In ACME Inc. case, they are more interested in solving our enterprise specific question answering task which falls to Closed Domain QA. LLM’s such as ChatGPT or Gemini, which has impressive abilities on Open Domain QA, in this scenario would not be a help at all since those models are not trained with ACME’s proprietary language data. The LLM that ACME’s AI team developed takes in documents or paragraphs that we have retrieved as input and customers’ questions, and provide answers according to the information that is contained in the documents or paragraphs. Because ACME’s LLM has been trained to answer questions from documents or paragraphs (closed domain QA), it will hallucinate far less and produce much less misinformation compared to general-purpose LLM’s such as ChatGPT or Gemini. As you can see in the diagram, ACME’s LLM automates what used to be a manual process requiring many human agents to answer questions for customers.
Sentiment Analysis
It is important to gauge whether ACME’s customers are happy and satisfied with the services that are provided. Acquiring customers’ approval to record the interactions with ACME’s customer service platform, AI technologies can be used to assess how well ACME’s customer service platform is doing. If a customer is using a voice driven service platform, all the voice data will be converted into text data by an speech-to-text AI model. If a customer is using a text driven service platform, no conversion is necessary. Once the customer interaction text data is attained, LLM’s Sentiment Analysis feature can be used to check the satisfaction of each customer interaction.
Sentiment Analysis refers to the process of automatically identifying the emotional tone of a piece of text, categorizing it as positive, negative, or neutral. It’s a crucial tool in Natural Language Processing (NLP).
With ACME’s LLM with Sentiment Analysis capability, the enterprise can attain invaluable customer satisfaction data by grading millions of customer interactions automatically.

Overview
ACME Inc. located in Santa Clara, California, is in the business of selling products and services to consumers. By utilizing various AI technologies, it wishes to achieve automation, efficiency, and cost reduction in its operation to deal with vast amount of language data: documents and voice recordings.
Speech-to-text (speech recognition) AI Model:
Convert all voice recording data to text data using the speech recognition AI model.
Construct Vocabulary for LLM (Tokenization)
Using proprietary enterprise language data statistics, create enterprise specific LLM vocabulary to increase the performance of the LLM to be trained.

Train LLM with Enterprise Proprietary Data:
ACME’s LLM is trained on enterprise proprietary data for better performance, less hallucination or misinformation.

Text Summarization:
Summarize documents and paragraphs using the LLM and organize the language data in the enterprise database.
Semantic Similarity:
Automate all customer inquiries via LLM’s Semantic Similarity feature.
Question Answering:
Automate customer questions with Question Answering of LLM.
Sentiment Analysis:
Gather millions of customer feedback and satisfaction report automatically using Sentiment Analysis of LLM.